
 热门精品专业
热门精品专业最后一步就是实现各种功能
语法高亮
首先我们要实现的是语法高亮.如下图所示:
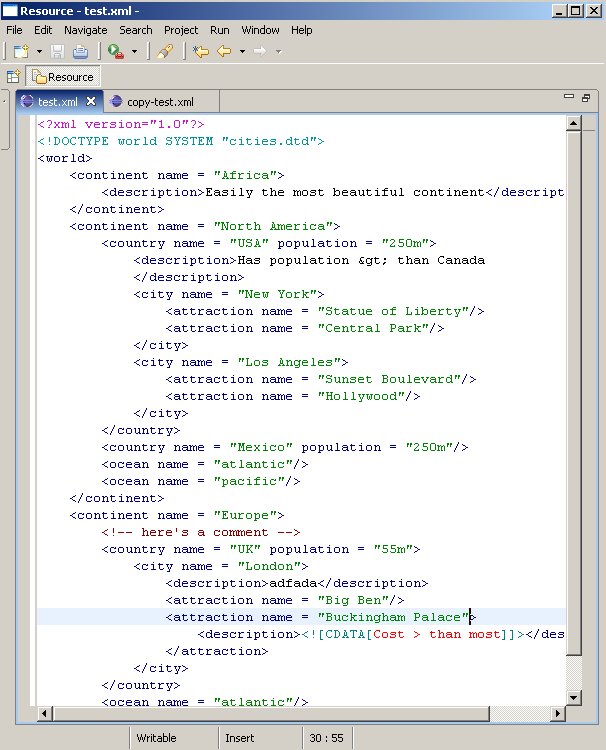
从本质上来说,语法高亮就是给分割后的Token指定相应的显示属性,在语法高亮的处理机制里面也需要用到Token, Scanner和Rule这些东西.通过复写SourceViewerConfiguration的getPresentationReconciler()方法来给指定的内容类型添加语法高亮的特性:
- public IPresentationReconciler getPresentationReconciler(ISourceViewer sourceViewer)
- {
- PresentationReconciler reconciler = new PresentationReconciler();
- DefaultDamagerRepairer dr = new DefaultDamagerRepairer(getXMLTagScanner());
- reconciler.setDamager(dr, XMLPartitionScanner.XML_TAG);
- reconciler.setRepairer(dr, XMLPartitionScanner.XML_TAG);
- dr = new DefaultDamagerRepairer(getXMLScanner());
- reconciler.setDamager(dr, IDocument.DEFAULT_CONTENT_TYPE);
- reconciler.setRepairer(dr, IDocument.DEFAULT_CONTENT_TYPE);
- ...
- return reconciler;
- }
在上面的代码中有一个IPresentationReconciler实例,他是用来监听底层的IDocument实例的变动,一个内容类型会跟一个IPresentationDamager和IPresentationRepairer实例相关联,当编辑文档时,将会给受影响的文档区域对应内容类型的IPresentationDamager实例发送消息,接着IPresentationDamager会返回一个IRegion实例,并将这些信息传递给IPresentationRepairer实例,该实例会对发生改变的区域重新设置显示属性.
上述过程听起来可能比较复杂,不过万幸的是我们并不需要自己去实现这些东西, JFace提供了一个DefaultDamagerRepairer来处理IPresentationDamager和IPresentationRepairer要做的事情,同时还提供了一个PresentationReconciler类用来将二者关联起来,而我们要做的就是告诉编辑器在使用给定的内容类型对文档进行分割之后的结构是怎样的,以及每一种文档类型的显示属性
DefaultDamagerRepairer的构造器需要一个ITokenScanner 参数,该接口跟分割Token Scanner非常类似,两种Scanner得到的Token都是IToken的一种实现,不同之处在于Token粒度不同,分割Token Scanner得到的Token是一个具有某种内容类型的文档区域,而使用语法高亮Scanner得到的Token是一段具有相同文本格式的字符串序列,显然后者的粒度更细
这里我们拿XMLTagScanner来说,该Scanner主要针对XML_TAG内容类型, 因此它得到的Token表示的是位于XML标识符之间的文本内容
- public class XMLTagScanner extends RuleBasedScanner
- {
- public XMLTagScanner(ColorManager manager)
- {
- Color color = manager.getColor(IXMLColorConstants.STRING);
- TextAttribute textAttribute = new TextAttribute(color);
- IToken string = new Token(textAttribute);
- IRule[] rules = new IRule[3];
- // Add rule for double quotes
- rules[0] = new SingleLineRule("\"", "\"", string, '\\');
- // Add a rule for single quotes
- rules[1] = new SingleLineRule("'", "'", string, '\\');
- // Add generic whitespace rule.
- rules[2] = new WhitespaceRule(new XMLWhitespaceDetector());
- setRules(rules);
- }
- }
XMLTagScanner继承了RuleBasedScanner,因此和我们在RuleBasedPartitionScanner中看到的一样,它也是使用某种规则处理机制来识别Token的
这里我们定义了三个规则:一个用于匹配双引号中的字符,一个用于匹配单引号中的字符,还有一个则用来匹配空格
为了给XML的标签名显示为蓝色,我们使用以下的代码,即给Token设置一个默认的颜色值:
- protected XMLTagScanner getXMLTagScanner()
- {
- if (tagScanner == null)
- {
- tagScanner = new XMLTagScanner(colorManager);
- Color color = colorManager.getColor(IXMLColorConstants.TAG);
- TextAttribute textAttribute = new TextAttribute(color);
- Token token = new Token(textAttribute);
- tagScanner.setDefaultReturnToken(token);
- }
- return tagScanner;
- }
内容格式化
格式化就是通过使用缩进和空格使文档结构化,从而更具有可读性, 格式化处理包括两个步骤:
第一步,为即将格式化的内容定义格式化策略,这些策略可以是全局性的,也可以是针对某个分割区域的.通过IFormattingStrategy接口来实现.
第二步,通过SourceViewerConfiguration实现类给ISourceViewer添加这些策略
格式化也会使用到分割处理,这让我们再一次体会到了掌握以及正确使用文档分割的重要性.下面我们就以最简单的TextFormattingStrategy来进行说明,该格式化策略用于处理嵌套在XML元素中的文本内容
- public class TextFormattingStrategy extends DefaultFormattingStrategy
- {
- private static final String lineSeparator = System.getProperty("line.separator");
- public String format(String content,
- boolean isLineStart,
- String indentation,
- int[] positions)
- {
- if (indentation.length() == 0)
- return content;
- return lineSeparator + content.trim() + lineSeparator + indentation;
- }
- }
这里我们通过继承DefaultFormattingStrategy并复写format方法来实现, 其具体做法是对文本内容进行trim处理,然后在文本前后加上换行符
上面的介绍可能太简单,在我们的实现类XMLFormattingStrategy中包含了更复杂的格式化处理代码,这里我们对其细节不再一一展开,有兴趣的读者可以自己去加以体会,可以说格式化处理是一项非常有挑战性的活儿,因为它还涉及到对选择的文本进行智能识别的处理,这个需要反复的实验才能得到理想的结果
通过重载SourceViewerConfiguration.getContentFormatter()方法可以非常容易的将格式化操作添加到编辑器中
- public IContentFormatter getContentFormatter(ISourceViewer sourceViewer)
- {
- ContentFormatter formatter = new ContentFormatter();
- XMLFormattingStrategy formattingStrategy = new XMLFormattingStrategy();
- DefaultFormattingStrategy defaultStrategy = new DefaultFormattingStrategy();
- TextFormattingStrategy textStrategy = new TextFormattingStrategy();
- DocTypeFormattingStrategy doctypeStrategy = new DocTypeFormattingStrategy();
- PIFormattingStrategy piStrategy = new PIFormattingStrategy();
- formatter.setFormattingStrategy(defaultStrategy, IDocument.DEFAULT_CONTENT_TYPE);
- formatter.setFormattingStrategy(textStrategy, XMLPartitionScanner.XML_TEXT);
- formatter.setFormattingStrategy(doctypeStrategy, XMLPartitionScanner.XML_DOCTYPE);
- formatter.setFormattingStrategy(piStrategy, XMLPartitionScanner.XML_PI);
- formatter.setFormattingStrategy(textStrategy, XMLPartitionScanner.XML_CDATA);
- formatter.setFormattingStrategy(formattingStrategy, XMLPartitionScanner.XML_START_TAG);
- formatter.setFormattingStrategy(formattingStrategy, XMLPartitionScanner.XML_END_TAG);
- return formatter;
- }
上述代码首选创建了一个formatter,然后通过formatter的setFormattingStrategy()方法给我们的每一个内容类型指定一个个格式化策略即可.
安徽新华电脑学校专业职业规划师为你提供更多帮助【在线咨询】


